ferris blogs stuff
Technical ramblings and other stuff
ferris blogs stuff  pulsejet: A bespoke sample compression codec for 64k intros
pulsejet: A bespoke sample compression codec for 64k intros
07 Jun 2021
pulsejet: A bespoke sample compression codec for 64k intros
In our 64k intros, in addition to synthesis, we (among other groups) typically use samples for small one-shot sounds that are notoriously hard to synthesize, yet crucial for the overall impression of a track (for example, kick/snare drums, vocal chops, etc.).
Of course, we don’t just store raw PCM data, because not only is it quite large, it doesn’t compress well. Instead, since at least the mid-2000s, the most popular “good enough” approach has been to use a GSM 06.10 codec to compress the sample(s), and then use a decoder shipped with Windows via the ACM API to decode the sample(s) during initialization.
The resulting compression ratio and audio quality that we get by using this codec on this kind of data isn’t particularly great, in fact it’s really bad by today’s standards. On top of that, even decoding a single sample takes ~10 ACM API calls, plus of a bunch of data juggling. Gargaj and I actually looked into this a bit, and it’s apparently ~265b, which is admittedly decent, but not exactly free. It’s also not tweakable - you get the rate you get, and that’s it. Still, it pays for itself, it’s worked for a long time, and the fact that Windows ships an encoder for it as well means it doesn’t require using/integrating any additional 3rd party code into our tooling, which, when it comes to codecs, can be pretty important! So it’s no surprise that the technique has been left alone for so long, but we can surely do better.
Nowadays, Windows gives us access to many more codecs, including some quite good ones, via the newer Media Foundation SDK. Some notable ones include MP3, AAC-LC/HE-AAC (though the latter of which doesn’t appear to have a matching encoder), and, while not documented (to my knowledge), Saga Musix tested and confirmed that MF can decode Opus as well (in a WebM container, but I assume it would also work using Ogg as a transport). Some of these codecs (particularly HE-AAC and Opus) can achieve quite good results, so on paper seem pretty attractive to use. A sensible coder might be quite happy to simply switch to a newer codec and call it a day, even if that entails integrating (as well as shipping/redistributing, in WaveSabre’s case) a 3rd-party encoder.
However, another alternative is to explore building our own codec. This is not something I’d done before, but I had a rudimentary understanding of how a few existing codecs worked, and I mean, how hard could it be? Audio codecs are notoriously complex beasts, but this is mostly due to trying to solve a lot of problems and/or optimizing for cases that we, as 64k artists, don’t actually care about. The more I thought about it, the more I couldn’t shake the feeling that it might be possible to identify some key ideas, trim the fat, and make a useful custom codec for this use case (just like we’ve done before with other data, like meshes and motion capture). And maybe, just maybe, it would result in something that’s actually competitive with “real” codecs, at least for the material we care about.
So, I got to work, and I made a codec (actually, I made about 10 or so depending on how you count them, but that’s beside the point), and I was quite pleasantly surprised by what I was able to put together, both due to its simplicity, but also, as we’ll see, its quality.
Side note: ps and hellfire recently informed me in a Twitter thread that this was explored and used in some late DOS-era 64k intros (this and this, among others). At that time, it was more popular to use tracked music for 64k’s, so sample data was quite significant. If I understand correctly, their approach was essentially to use a filter bank and heavily quantize or skip frequency bands with little content throughout the duration of the sample, and leave entropy coding to the executable packer. This had reportedly somewhat mixed results, though it was still useful; to my ears, these songs actually don’t sound at all degraded compared to other sounds of the era! However, when softsynths started becoming popular, this idea was abandoned. Still, as we’ll see, the core idea is not that far from the codec I’ll discuss in this post if you squint hard enough, and I was quite pleased (and frankly, only mildly surprised) that this space had actually been explored somewhat in the demoscene before.
Project pulsejet
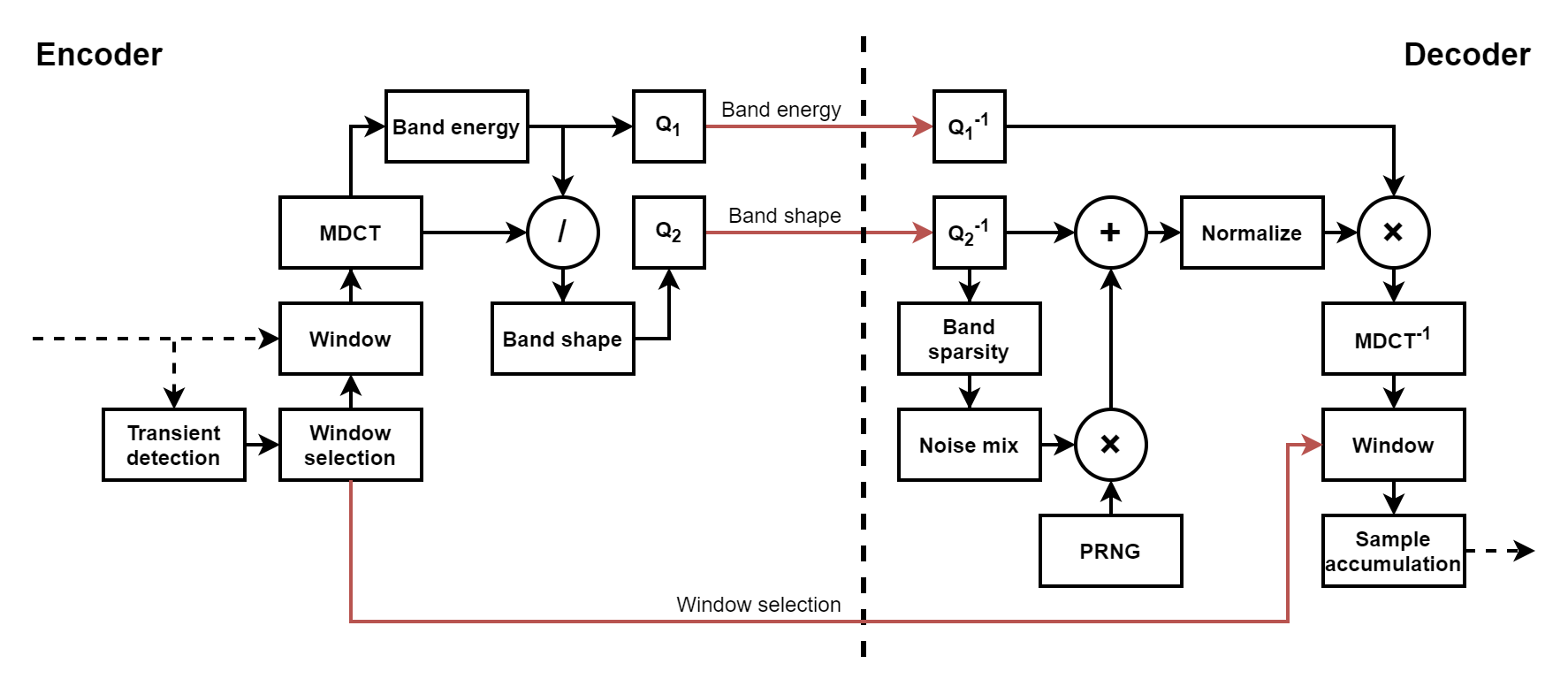
pulsejet is what I came up with: a bespoke, perceptual sample compression codec for 64k intros. As such, it’s designed to be integrated into WaveSabre to replace our current use of GSM 06.10 (though this integration hasn’t actually happened yet, because I was so excited about the project on its own that I wanted to release it and blog about it first!), and surely it can be used in other contexts as well (eg. other synths, or in some kind of compressed tracker format perhaps). It works with mono (single channel) floating point samples at 44.1khz (fullband), though technically just about all other sample rates are also supported (eg. dropping a sample down to 1/2 or 1/4 of that rate is often used as easy ways to save space), just not psychoacoustically optimized for. Target bit rates are anywhere from 0kbps-70kbps or so, with 32-40kbps as a sort of “sweet spot” where most relevant material should sit comfortably in a rate/distortion sense. For reference, 70kbps is about what GSM 06.10 targets if you feed it 44.1khz input rather than its usual 13kbps target, which you get with its intended 8khz sample rate (yes, this is abusing the codec!).
Like basically all other perceptual audio codecs, compression in pulsejet is achieved primarily by (losslessly) transforming the input signal into a representation that’s easily compressible, which is then compacted via quantization (removing perceptually irrelevant information) and entropy coding (removing redundant information). It’s the encoder’s job to do all of this and to make smart decisions which hopefully minimize audible distortion while targeting a user-specified bitrate. The decoder, on the other hand, is by design not smart - it simply unpacks/dequantizes the data, reverses the lossless transform, and makes some last-ditch attempts to hide artifacts introduced in the process.
pulsejet takes a lot of ideas from Opus, and more specifically, its CELT layer, which is used for coding musical signals. For the rest of this post, I’ll just refer to CELT, though it’s important to note that I’m specifically referring to the modern-day version of CELT which is present in Opus (which differs from the original standalone work).
CELT is an MDCT-based transform codec, and it’s actually kindof a funky one. One of its most notable design constraints is that it supports significantly lower latencies than other transform codecs. As such, it often uses much smaller MDCT frames than would otherwise be used, which means more frames represented in the bitstream per unit time. Because of this, many of its design decisions focus on reducing per-frame bitstream data as much as possible. “Traditional” transform codecs like MP3 and AAC signal per-band quantization parameters in the bitstream. In CELT, many of these decisions are instead made implicitly in both the encoder and in the decoder. This provides a bit less flexibility in terms of encoder implementations (and potential further improvements targeting the same decoder(s)), but reduces the bitstream size significantly, and surprisingly, it performs exceptionally well even with these constraints, and even with larger frame sizes when compared to codecs optimized for archival/storage with high fidelity. Due to this impressive performance and emphasis on reducing per-frame information as much as possible, modeling pulsejet after CELT seemed like a reasonable choice - or more accurately, a “CELT lite” of sorts.
MDCT, windowing, critical bands
Like CELT, pulsejet is also built around the MDCT. Unlike CELT, however, pulsejet isn’t at all concerned with codec latency, so we can revisit some fundamental decisions. Instead of supporting several frame sizes or having windows with a low amount of overlap, pulsejet uses fixed 1024-sample frames (~23ms at our target sample rate of 44.1khz) with the Vorbis window to maximize frequency domain resolution and to reduce spectral leakage as much as possible, all while also minimizing decoder complexity, since the window is so simple to express. Larger window sizes were considered as well to reduce the amount of frames overall, but dropped, as it actually performed worse in the end at similar rates; ~20ms appears to be aligned with how often frequency content changes characteristics in most relevant material. Still, ~20ms is somewhat long, so a downside of this (as well as the with window choice) is that it doesn’t have particularly good time-domain resolution. To work around this, pulsejet switches between long (~23ms) and short (~23ms/8, or ~2.8ms) windows (with special transition windows when switching) as outlined in the Vorbis spec when transients are detected. I also tried interleaving coefficients like CELT does, but this turned out to break a part of the codec I’ll talk about shortly very badly, and wasn’t really all that much simpler.
Speaking of simplicity, the IMDCT used in the pulsejet decoder is actually the simplest possible construction with O(N^2) complexity, which we get away with because we’re encoding short one-shot samples. If we weren’t, we’d probably have the space to afford a faster impl anyways, so maybe in the future we can swap in a larger/faster one at build-time if desired.
As with most MDCT-based transform codecs, after the MDCT is applied, we separate the resulting bins into critical bands that approximate the Bark scale for further processing.
Gain/shape coding
The most crucial idea that pulsejet lifts from CELT is that of constrained energy (the “CE” in “CELT”). Perceptually, the human auditory system is quite sensitive to the amount of energy present in each critical band (forming the spectral envelope in aggregate, in coarse detail), but it’s less sensitive to how that energy is distributed within each band (fine detail). So, like CELT, pulsejet codes the bins in each band in a gain/shape fashion: a scalar band energy is computed and coded with relatively high precision, and the bins are then divided by this (unquantized) energy, resulting in a unit-vector band shape, which is coded with relatively low precision. This partitioning is not only crucial in terms of making it easy to spend a good amount of bits where it’s most perceptually relevant, but perhaps even more importantly, it gives the codec quite a bit of freedom in terms of how it treats each band, since it’s still able to preserve energy in the end. The simplest example of this is that the precision used for the shape vectors is actually dynamic and depends on the band energy, such that bands with higher energy use more bits, and vice versa. As it turns out, this actually approximates the intra-band masking modeled explicitly in traditional transform codecs implicitly, which also happens to simplify the encoder implementation. Another example of this is how pulsejet handles sparse band collapse, which I’ll get to a bit later.
Band energy is coded as a single 6-bit unsigned integer per-band per-frame. The energy is scaled logarithmically and then uniformly quantized. Additionally, the energy between subsequent frames for each band tends to be strongly correlated, so we use the previous frame’s energy for the current band as a predictor. Since we’re not concerned with packet loss/streaming (like CELT is), we simply use the previous frame’s energy as-is, without any sort of scaling that would “dampen” the predictor over time. This typically results in better predictions, and is slightly simpler in the decoder.
Band shape is coded by breaking down the unit shape vectors into scalar components, and quantizing those separately. This typically performs worse in a rate/distortion sense than dedicated vector quantization solutions, but is significantly simpler to implement, even compared to schemes with algebraic codebooks (again, smaller decoder). I did consider/explore some VQ options, but they haven’t resulted in anything compelling thus far (more on that later). One thing that’s kindof fun here is that we don’t actually have to transmit/derive the scale factor used for this quantization, as we’re going to normalize the vector again after dequantization (since quantization error will usually distort the vector’s magnitude, which we’ll need to fix to for energy conservation). Since the quantization scale factor only affects the magnitude of the vector (in the absense of quantization), normalization will simply cancel this scale factor out.
Entropy coding (or lack thereof)
When it comes to the actual bitstream, pulsejet is unique in that it does not contain an entropy coder, or really any bit packing for that matter. This is because in 64k, we’re going to be passing the encoded stream through a very powerful lossless compression engine in the executable packer (typically squishy or kkrunchy). This obviously simplifies the decoder implementation by not having to include an entropy stage, but it also has a few other interesting implications:
- The lossless compressor has to be able to find patterns in our data, so we should group similar data together in the encoded representation to allow it to do this. This is in contrast to using an entropy coder, where we can insert symbols in pretty much any order/length, so long as the encoder/decoder are in agreement about these parameters (and this is usually implicit in the construction of the codec).
- Since we don’t control the actual model that’s used for the data (beyond grouping/decorrelation that we do in the codec before the entropy stage already), the theory suggests that we won’t be able to achieve optimal coding performance for our symbols. While this is true assuming ideal models (which are typically order 0 and assume a mostly-static probability distribution), empirically, the backend typically actually outperforms our assumed optimum. This suggests that there are additional correlations in the data that these models don’t capture, but a more powerful compression engine (with more context) can and does.
- The above point is moot if we have a suboptimal entropy coding stage before the exe packer’s stage, as this would effectively obfuscate the data such that these additional correlations would be impossible for the adaptive models to pick out. Instead, we should align all of our data to fixed record sizes that are multiples of 8 bits.
- Due to this alignment, we can actually get away with removing some signaling that would otherwise be present for correct decodability. For example, with quantized bin coefficients, we would typically have to signal a scale factor in order for the decoder to be able to decode the symbols at all. However, if we rely on a separate backend, we can just encode all symbols with their maximum number of bits that the highest quantization level would use (or even more bits, if we want to align the symbol width to a byte boundary), and only use subsets of these symbols for lower levels. Again, this implies that we’re wasting code space, but empirically, outperforms the explicit models most of the time.
The only really negative consequence of not including an entropy coder is that our encoder isn’t able to estimate the actual achieved bitrate for a certain set of symbols as accurately. This is detrimental for CBR, but this is yet another constraint we don’t actually have to deal with for our use case. The pulsejet encoder simply calculates order 0 statistics for various parameters and adjusts the estimated bit counts to make them ~15% lower, which in practice tends to match the actual compressed size reasonably well, at least on average.
Sparse band collapse handling
While the above is certainly enough to build a decent codec, we can do better. The most significant issue I recognized in my experiments was that when a band gets allocated a small number of bits (a case that is especially common with higher frequency bands, which both contain more bins than low frequency bands, but are also less significant perceptually, and are thus typically allocated few bits to begin with), the quantization process causes the shape vector to “collapse” into a new shape with zero or very few nonzero components. In the worst cases, this causes significant tonal ringing artifacts (“birdies”), even when the original source signal wasn’t particularly tonal to begin with. It can also cause a band to collapse entirely, resulting in a “hole” in the spectrum, even though we’re still coding a nonzero amount of energy there.
To counteract this, for each band, the pulsejet decoder keeps track of how many bins were zero after dequantization. This constitutes a “sparsity” metric. When a band is found to have sparsity above a certain threshold, the decoder will generate a random (ideally uniformly distributed, but it turns out that isn’t crucial, so we approximate a bit here) unit shape vector and mix it in with the dequantized vector based on the sparsity. This occurs before normalization so that the band energy is still preserved. This added noise produces a signal that deviates from the original signal (often significantly). However, perceptually, this sounds much better than doing nothing or other alternatives (for example, spectral folding (CELT), which I used in earlier versions of the codec and can often sound quite harsh and adds “misplaced” harmonics, or spectral band replication (some AAC variants) which can require relatively sophisticated processing in the decoder) on both tonal and noise-like signals, while also being very simple to implement. I found that this kind of collapse handling was actually extremely important for perceptual fidelity, especially when using scalar quantization for shape vectors, due to the potentially significant distortion it can introduce.
Results
First, let’s briefly talk about decoder size, since that’s something we have to consider when shipping a custom codec in an intro. pulsejet’s decoder is currently about 750 bytes large, give or take, depending on what else is in the executable and which packer is used. This is admittedly a bit larger than I had hoped (I was hoping for something in the 300-500 bytes range), but it can surely be code golfed more, and I expect this will improve in future library versions.
Next, listening tests. But before that, we should talk about my test setup and what I’ve done to get reasonably fair comparisons.
As mentioned earlier, the samples we typically use are 44.1khz mono, or perhaps downsampled to 1/2 or 1/4 (22khz or 11khz, respectively) in some cases to save space. Target bit rates are 0-70kbps or so, with 32-40kbps being the range I was most interested in. As such, I’ve only tested with codecs that are able to target these same parameters, and all of the samples in this (relatively small) corpus are already converted to that format to begin with. The exception to this is “raw”, which represents the original .wav input, at about 700kbps. For fun, I also ran all of the other codecs with that rate as a target as long as they supported it.
Additionally, since we’d ship the encoded samples in a packed executable, all of the encoded samples (not just the pulsejet ones) have been run through a hacked version of squishy that acts as a standalone compressor without all of the fancy PE/exe handling shenanigans, and with no added headers on the output. The byte counts and bit rates listed are calculated from the original sample lengths in seconds, and the resulting encoded-then-squished byte counts.
The opus setup is actually a bit synthetic, as the opusenc tool that comes with opus-tools churned out surprisingly low quality samples at the same compressed sizes as other codecs, even when tweaking parameters to give it every advantage I could. So, instead, I used libopus directly and custom framing (literally just integer frame sizes), so there’s as little transport overhead as possible, likely far less than an actual container would add. I doubt any OS could ever decode such a stream (you’d need direct access to an Opus decoder), but I wanted some kind of compression performance ceiling to compare against initially, so I wanted to give it every advantage I could.
Similarly, the HE-AAC and LC-AAC results here are generated using Apple’s notoriously good AAC encoder via a janky qaac setup. This indeed produced very good quality samples, even though it appears to only be able to output ADTS, and not ADIF, which might add some overhead (or I’m just misunderstanding, and it doesn’t matter). Either way, it performed so good that I didn’t look further into it. I also didn’t tweak the encoder’s lowpass settings (or any other settings for that matter), which may or may not have given better results at lower rates (though this probably depends on the material anyways).
I’ve also included MP3 (via ffmpeg/libmp3lame), but clearly this is just garbage at these low rates. Vorbis didn’t fare much better in my quick tests via winLAME, so those aren’t included in the matrix. I assumed WMA would fare similarly, and didn’t even test it.
Finally, some notes about the individual samples and why they were chosen:
44-kick.wav/44-clap.wav/22-kick.wav/22-clap.wav: These samples are fairly bog-standard kicks/claps, sampled at both 44.1khz and 22khz, respectively, so test that we can still halve the sample rate and get decent results in a pinch (even though pulsejet supports a very finely adjustable target bit rate, and tweaking that is preferred to this technique). These samples don’t have super interesting stuff going on otherwise.foryou.wav: This is a very distorted/processed vocal sample with loads of interesting frequency content. It’s a fair bit longer/larger than the vocal cuts we usually include in a 64k (though pulsejet may change that for future intros).hey.wav: Also fairly distorted/processed, but much cleaner/shorter than the above. This was meant to represent a cleaner, tonal signal, without much transient information, and is more representative of the kinds of vocal cuts we’ve used in intros previously.kick-bong.wav: I wanted to try a kick sample that was really messy and grungy and didn’t have a super clearly defined transient, but still had a characteristic overall sound.kick-vr.wav: Super hard distorted crazy kick. We use these things all the time, so we’d better handle them well!matzobreak.wav: This is actually a funny one, because it’s quite rare to include an entire drum loop in our intros (though we may include some cuts from one). This was actually added early on as a pathological, out-of-scope case that I didn’t expect to be able to handle very well (and we could still use improvement here in the current codec). Even worse would probably be a music clip with both tonal and noisy content occurring simultaneously, and I should probably add such a sample now that the codec has improved.snare-anvil.wav/snare-ring.wav/snare-tight.wav: A few different snares that are a lot like what we’ve used in intros previously. Each one has different characteristics and should be handled well.
With all of that out of the way, here’s the latest test matrix. It’s organized by sample. Rows represent codecs, cols represent target bit rates, which often differ from the actual achieved rates, so when comparing, try to find table cells in nearby columns that have similar byte counts, rather than just going down the same column, as this is more fair. Empty cells represent codec/target rate pairs that aren’t supported. All samples have been re-encoded to .wav, so what you’re hearing on this page is unaltered, round-trip audio and it’s more or less guaranteed to work regardless of which browser you use.
This corpus is, of course, fairly small, and surely there are cases that aren’t covered. At the same time, there’s definitely some variety in there, so I think it’s safe to draw some conclusions about the work so far. To my ears, the following is generally true:
- GSM is pretty crap on almost everything. It’s usable, but has a very high noise floor. Interestingly, it does handle transients fairly well, but I suspect this is mostly due to its very short windows (originally intended to be ~20ms at 8khz for speech modeling, but dropping down below 4ms at 44.1khz). However, the rest of the samples often become a bit of a noisy wash when compared with other codecs, even at >2x the target rate. Ironically, this is especially true with the vocal samples.
- MP3 is also pretty useless at most of the rates we’re interested in. Even in the higher rates tested, it can get pretty ringy.
- LC-AAC is, somewhat unsurprisingly, not that great. It’s a shame that this is the only AAC variant that Windows ships an encoder for.
- Almost all of the material, when coded with pulsejet, is competitive with Opus and HE-AAC at similar byte counts. Exceptions to this are
hey.wav, which exhibits more noticeable quantization noise, andmatzobreak.wav, which has some low-frequency rumble, even at the highest rates. - For the most part, pulsejet samples appear to fare better than other codecs in the 16-32khz range (again, looking at final rate, not the target rate), but of course not always.
- Many pulsejet samples actually appear to be somewhat usable in the very low ranges, eg. 4-8khz. This was a pleasant surprise; to be honest, I added these rates out of pure curiosity, but when initial tests seemed somewhat promising, I kept them around. This is also one of the main reasons why pulsejet employs simple noise injection instead of band folding; at these very low rates it sounds much better (you can hear Opus collapsing pretty hard down there, for example, and I’m not just talking about its lowered sample rate).
- We can attempt to account for decoder size, with pulsejet’s decoder clocking in at 750 bytes or so and assuming a MF-based decoder to take ~350 bytes or so, by comparing other codecs to pulsejet’s output when pulsejet’s output is about 400 bytes lower than the other codec(s). These are also surprisingly competitive on most drum sounds, though I would say HE-AAC generally sounds the best to my ears, with Opus not far behind, and pulsejet, while better in a few cases, is generally a bit worse than its counterparts.
Of course, all of these conclusions are my own, and any listening test will lend itself to a certain amount of subjectivity/bias, so I encourage you to listen for yourself and make your own judgments.
Wrapping up/future work
At this point, the results are clearly good enough to validate this effort, and I suspect future improvements will continue to close the gap moving forward (both in terms of improved quality and smaller decoder size hopefully), ideally to the point where it usually won’t make sense to use anything else, even with the relatively large decoder. The codec today (especially the encoder) is admittedly crude and there’s nothing in there that couldn’t have existed 10-20 years ago. Still, in any given problem domain (however small/niche), it’s nice to beat the crap out of a solution everyone’s been using for years and is competitive with what they should have been using instead, and it’s just so wonderfully satisfying to come up with a distillation of ideas that performs this well while being this simple and straightforward.
In terms of specific things I want to explore in the future, here’s a few:
- Encoder improvements. Especially regarding bit allocation (which we don’t have to signal) and especially for better hiding quantization noise in highly tonal signals (eg.
hey.wav, which I suspect is fixable). Another fun potential improvement without any decoder changes could be to detect sufficiently noisy bands and just force-quantize all of the bins to zero. This would cause the decoder to fill the band entirely with noise, which might actually perceptually indistinguishable, as long as the encoder did so judiciously, and would certainly save bits in these cases. Another thing is that transient frames appear to use too few bits often, leading to more bands collapsing than we would like. It might be a good idea to reserve some additional bits for these frames and spread the difference over subsequent long frames, or something. - Faster encoder, and perhaps also faster decoder. The bottleneck in both currently is the naive (I)MDCT formulation. For decoding a handful of short samples, this should be completely manageable, and the naive approach makes sense. However, for longer samples and/or test setups, at least in the encoder, it really just hurts iteration time, so at least having a variant of the encoder with a faster approach would make sense.
- Vector quantization experiments, particularly with PVQ (again, used in CELT), which I did start playing with, but needs a lot more work, especially to work around signaling/deriving the
Kparameter, all without adding too much code to the decoder. Perhaps it’s worth exploring other VQ methods as well, though there aren’t that many that I’m aware of that are very attractive, admittedly, and trying to come up with better schemes myself hasn’t yielded anything worthwhile (unsurprisingly). - Some kind of prediction scheme for band shape vectors (I actually wonder if scalar quantization is going to be more straightforward for this and win in the end when it comes to decoder complexity, but needs experimentation). Earlier CELT had a relatively complex pitch prediction scheme that turned out to only really achieve minor gains (and thus was dropped in later version of the codec, including what went into Opus), but the authors’ further work on Daala (specifically, perceptual vector coding) appears to be much more promising/effective.
- Double-check various ranges/scales for encodings, eg. band energy. Are we wasting any bits/range potentially?
- Stereo? It may make sense to spend some of the space gained on fidelity in more dimensions.
- More left-field codec designs, perhaps inspired by Ghost.
- More and more testing and listening, ideally by more people!
Edit 14/12/2021: Small grammar fix.
Edit 09/06/2021: Clarified why interleaving short MDCT bins for transient handling didn’t work very well.
07 Jun 2021